Kennen Sie das Problem? Sie haben einen Text mit diversen persönlichen Daten und möchten diesen mit Hilfe von KI optimieren, verändern oder erweitern. Doch Sie dürfen diese Daten nicht einfach so verwenden, da persönliche Informationen enthalten sind, die dem Datenschutz unterliegen. Genau hier kommt das Thema Anonymisierung Pseudonymisierung (unterschied gerne hier nachlesen: Wikipedia) ins Spiel.
Besonders in unsicheren und aufwühlenden Zeiten wie heute ist der verantwortungsvolle Umgang mit sensiblen Informationen wichtiger denn je. Gerade im Management stehen Sie vor der Herausforderung, Innovation und Datenschutz miteinander zu verbinden. Die gute Nachricht: Mit der KI-Workflowplattform n8n lassen sich sensible Daten nicht nur effizient, sondern auch DSGVO-konform pseudonymisieren – und das ohne technisches Spezialwissen.
Was bedeutet Pseudonymisierung eigentlich?
Pseudonymisierung heißt: Persönliche Informationen wie Namen, Adressen oder Kontodaten werden so verändert, dass sie keiner Person mehr zugeordnet werden können. Der Personenbezug bleibt erhalten, aber nur mit zusätzlichen Informationen (Schlüssel) rekonstruierbar. Damit sind die Daten laut DSGVO weiter „personenbezogenen Daten“, erfüllen aber entsprechende Regelungen, solange die Zuordnungstabellen getrennt gespeichert werden.
Warum ist das für Unternehmen wichtig?
Rechtssicherheit: Pseudonymisierte Daten lassen sich in der Konstellation unter Berücksichtigung der DSGVO-Regeln auch in Systemen nutzen, die ggf. die DSGVO-Regeln nicht zu 100% erfüllen. Das reduziert Haftungsrisiken und vereinfacht viele Prozesse.
Mehr Flexibilität: Sie können Daten für Analysen, KI-Modelle oder Berichte nutzen, ohne Datenschutzprobleme.
Schnelligkeit & Skalierbarkeit: Automatisierte Workflows sparen Zeit und Ressourcen.
n8n: Die Plattform für sichere Datenprozesse
n8n ist eine moderne KI-Workflowplattform, die Unternehmen jeder Größe nutzen können – ohne Programmierkenntnisse246. Sie können n8n lokal auf eigenen Servern betreiben und behalten so die volle Kontrolle über Ihre Daten56.
Vorteile für das Management:
- Transparenz: Jeder Schritt im Workflow ist nachvollziehbar.
- Flexibilität: Workflows können per Drag-and-Drop angepasst werden.
- Datenschutz: Selbst bei Cloud-Nutzung bleibt die Kontrolle über die Daten erhalten56.
So funktioniert ein Pseudonymisierungs-Workflow in n8n
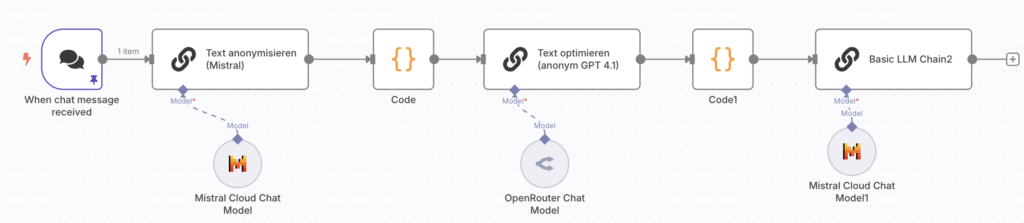
- Eingangsdaten: Zum Beispiel Text mit diversen persönlichen Daten oder eine Excel-Liste mit Kundendaten.
- Automatische Erkennung sensibler Daten: n8n sucht nach Namen, IBANs, Adressen usw.
- Pseudonymisierung: Die gefundenen Daten werden durch neutrale Platzhalter ersetzt (z. B. „[[PERSON_1]]“ statt „Max Mustermann“). Die Zuordnungstabelle wird separat gespeichert.
- Weiterverarbeitung: Die pseudonymisierte Daten können gefahrlos in n8n KI Agenten Nodes oder für Analysen, Berichte oder KI-Anwendungen genutzt werden.
- De-Pseudonymisierung: Im letzten Schritt werden die Daten wieder über eine DSGVO konforme Methode mit den persönlichen Daten verknüpft.
Mistral oder Regex? Zwei Wege, ein Ziel
Wir haben zwei grundlegend verschiedene Ansätze intensiv ausprobiert:
Ansatz 1: Mistral-Lösung mit European AI
Bei dieser Variante wird ein großes Sprachmodell (LLM) genutzt, das von einem europäischen Unternehmen entwickelt und gehostet wird und per API zur Verfügung steht. Das Modell erkennt und pseudonymisiert personenbezogene Daten über präzise Prompts. Dieser Ansatz funktioniert in vielen Fällen erstaunlich gut – manchmal sogar besser als die Regex-Variante. Gerade bei ungewöhnlichen Schreibweisen oder in sehr freiem Fließtext kann die KI durch ihr Kontextverständnis punkten.
Ansatz 2: Regex-basierte Lösung ohne Language Model
Bei dieser Variante kommt kein Sprachmodell zum Einsatz, sondern ausschließlich Regex-Code, der direkt in n8n ausgeführt wird. Für die meisten klassischen Anwendungsfälle – wie Namen, Adressen, Kontonummern oder Geburtsdaten – reicht diese gut gemachte Regex-Lösung vollkommen aus, um die Anforderungen der DSGVO sicher und effizient zu erfüllen. Sie ist schnell, kostengünstig, läuft vollständig lokal und ist für Audits leicht nachvollziehbar.
Was ist eigentlich Regex?
Regex steht für „Regular Expression“ – eine Art Suchmuster, mit dem man gezielt bestimmte Daten im Text erkennt und ersetzen kann. Beispiel: Mit einem Regex-Muster wie
[A-Z]{2}\d{2}\s?(\s?\d{4}){4,6}
findet man zuverlässig deutsche IBANs, egal ob sie mit oder ohne Leerzeichen geschrieben sind. So können auch große Datenmengen automatisiert und regelbasiert pseudonymisiert werden.
Die Regex-Lösung haben wir um spannende Funktionsbereiche aus der Open Source Lösung Microsoft Presidio angereichert, um eine möglichst kompakte aber dennoch umfangreiche Lösung zu erhalten.
Zwei wichtige Optimierungen aus der Praxis
1. Kontextbewusste Erkennung:
Unsere Regex-Lösung in n8n prüft nicht nur auf das reine Muster, sondern erkennt auch typische Kontextwörter wie „Geburtsdatum“, „Kontonummer“ oder „Rechnung“. So werden auch Daten pseudonymisiert, die in unterschiedlichen Schreibweisen oder Sätzen vorkommen.
2. Intelligente Platzhalter:
Statt einfach alles als „[[NUMMER]]“ zu ersetzen, werden die Platzhalter nach Typ unterschieden – etwa [[PERSON_1]], [[BANK_IBAN_2]] oder [[EMAIL_3]]. So bleibt der Text auch nach der Pseudonymisierung für Analysen und Auswertungen nutzbar, ohne Rückschlüsse auf einzelne Personen zuzulassen.
Fazit für Entscheider
Beide Lösungen haben ihre Berechtigung:
- Die Mistral-Lösung ist ideal, wenn viele Freitexte, unklare Formate oder mehrsprachige Inhalte verarbeitet werden müssen.
- Für strukturierte, deutschsprachige Daten und typische Geschäftsprozesse genügt oft die Regex-Lösung in n8n – und das mit maximaler Effizienz und minimalem Aufwand.
Unser Tipp: Starten Sie mit einer Regex-Lösung in n8n. Sie ist schnell implementiert, auditierbar und spart Kosten. Für Spezialfälle können Sie später immer noch auf KI-Modelle wie Mistral zurückgreifen.
So bleibt Ihr Unternehmen datenschutzkonform, flexibel und effizient – ganz ohne unnötige Komplexität.
Interessiert am Regex Code? Melden Sie sich gerne und lassen Sie uns darüber sprechen, wie Sie das Thema sinnvoll einsetzen können.